About
OrthoWiki
OrthoWiki is a curated orthopaedic surgery reference covering the shoulder, elbow, wrist and hand. It is written, edited and clinically reviewed by Dr Kieran Hirpara, Specialist Orthopaedic Surgeon, and published by CQ Hand + Upper Limb. Patient-facing articles explain conditions and procedures in plain language; the matching clinician pages summarise the peer-reviewed evidence behind them.
Topic synthesis is generated using large language models prompted against an indexed corpus of the orthopaedic literature, then edited and reviewed by Dr Hirpara. Every claim is referenced; the source DOI is listed in each topic's references list. Reviewed topics display the reviewing clinician and the date of review. This is a reference aid for clinicians familiar with the literature and an educational resource for patients — not a substitute for individual medical advice.
Text content is shared under the Creative Commons BY-NC 4.0 licence — free for non-commercial reuse with attribution. Figures and images may be separately licensed; check each caption or source link for the individual terms.
OrthoWiki is catalogued on Wikidata.
How OrthoWiki is built¶
Full transparency on the pipeline behind every page. OrthoWiki is produced by an automated, open-source toolchain that turns a library of peer-reviewed orthopaedic PDFs into referenced clinician summaries and plain-English patient guides — each one then reviewed by Dr Hirpara before publication. Nothing here is hidden; the tools are listed, with links, at the end.
From a PDF to indexed evidence¶
1. Source library. Primary sources — journal articles and textbook chapters — are collected as PDFs, organised by source. Each PDF is a primary reference.
2. PDF → text (a three-stage converter cascade). Every PDF is converted to Markdown by an automatic cascade that tries the cheapest accurate method first and falls through on failure:
- docling (IBM's open-source document parser, using its TableFormer model for tables) extracts the text layer.
- if that under-produces — e.g. a scanned page with no text layer — LiteParse (a fast, CPU-only spatial-text extractor) is tried.
- for true scans, a vision-language model (Qwen3.6 VLM) performs OCR page by page.
3. Citations & metadata (CrossRef). The article's DOI is read from the PDF text and looked up against the CrossRef API, returning authors, journal, year and volume/issue/pages — formatted into a JBJS-Vancouver citation. Articles without a DOI fall back to a filename-based citation.
4. Region tagging (MeSH). Each article's PubMed MeSH descriptors and author keywords (fetched by DOI) are mapped to an anatomical region — shoulder, elbow, wrist, hand and beyond. A title-keyword fallback covers articles with no MeSH data.
5. Embedding & indexing. Article text is split into section-aware chunks (~400 tokens, tracking page numbers) and embedded with MedCPT — NCBI's medical bi-encoder, 768-dimensional. Vectors are stored in a Qdrant vector database; content-hash de-duplication stops the same PDF being indexed twice. Topics, articles, the article↔topic links, monthly digests and evidence levels live in a PostgreSQL database (with the pgvector extension).
6. The ingest pipeline. New PDFs flow through one ordered pipeline — seed → CrossRef → MeSH → classify → cite → index — with each article's progress tracked in a jobs table. Articles are classified to topics by their MeSH terms plus title keywords.
How an article is written¶
7. Retrieval (two-stage). For a topic, the relevant literature is gathered by a two-stage search: a fast MedCPT bi-encoder retrieval over the vector database, then a MedCPT cross-encoder re-ranks the candidates for precision. Region and source filters keep the evidence on-topic.
8. Synthesis (two passes). The gathered key articles become an evidence pack. The
pipeline extracts a short digest of each article and scores each for relevance, then
runs a two-pass synthesis: a first pass drafts the article from the evidence pack, and
a second augment pass refines structure and readability. A Vancouver ## References
list is built automatically, and a cross-reference pass adds inline DOI links and a
See Also section. A token-budget guard keeps very large topics inside the model's
context window.
9. Clinician-first, then patient. The clinician page is synthesised from the literature. The patient page is then derived from that same clinician evidence pack, re-voiced into plain English. For unusually broad ("danger-tier") topics, a deeper mode first digests every candidate article before synthesis.
10. Evidence levels. Where the source reports it, each article carries an Oxford level of evidence (1 = highest … 5), captured at the metadata step. The Evidence Explorer's pips aggregate these per topic (the highest available level plus the count of high-level sources) — a genuine signal, never a fabricated grade.
Operations, review & output¶
11. Recovery & complications sidecars. For each operation, a structured
recovery-and-complications.json sidecar is generated from the evidence: a recovery
timeline plus complications with their reported rates. This single file drives the
recovery-at-a-glance strip, the complications table and the consent handout PDF.
Non-operative (information) topics skip it cleanly.
12. Human review & hand-editing. Automated synthesis produces a draft. Dr Hirpara reviews and edits it. Pages that are hand-edited are flagged hand-authored and protected — the weekly automated pipeline skips them, so human edits are never overwritten. Reviewed topics show the reviewing clinician and the review date.
13. Cross-linking. A cross-reference pass links related topics (the See Also lists) and turns every citation into a clickable DOI link.
14. PDF handouts. At publish time, WeasyPrint renders each patient page into a
printable handout.pdf; operations also get a consent-handout.pdf carrying the recovery
strip and complications table. These PDFs feed the practice clinic and are served from
this site.
Illustrations & figures¶
The anatomical illustrations, surgical diagrams and rehabilitation figures are produced separately, in a consistent hand-inked "house style", by OrthoWiki's image toolchain (cqhul-imagestyle). Two sources feed it:
- Curated open-licence images — existing diagrams and photographs from Wikimedia Commons and similar repositories, used under their own Creative Commons terms; each figure's individual licence and source are credited in its caption.
- De-novo illustration — where no suitable open image exists, a bespoke figure is generated locally and licensed CC BY-NC 4.0, like the text.
How the de-novo figures are made. Generation runs entirely on the practice's own GPU workstation through ComfyUI — there is no third-party image service, and all model weights are held locally. For the rehabilitation diagrams, a single recurring, faceless "house character" (kept consistent across a set of canonical front / back / profile / kneeling / lying reference views) keeps the figures visually uniform.
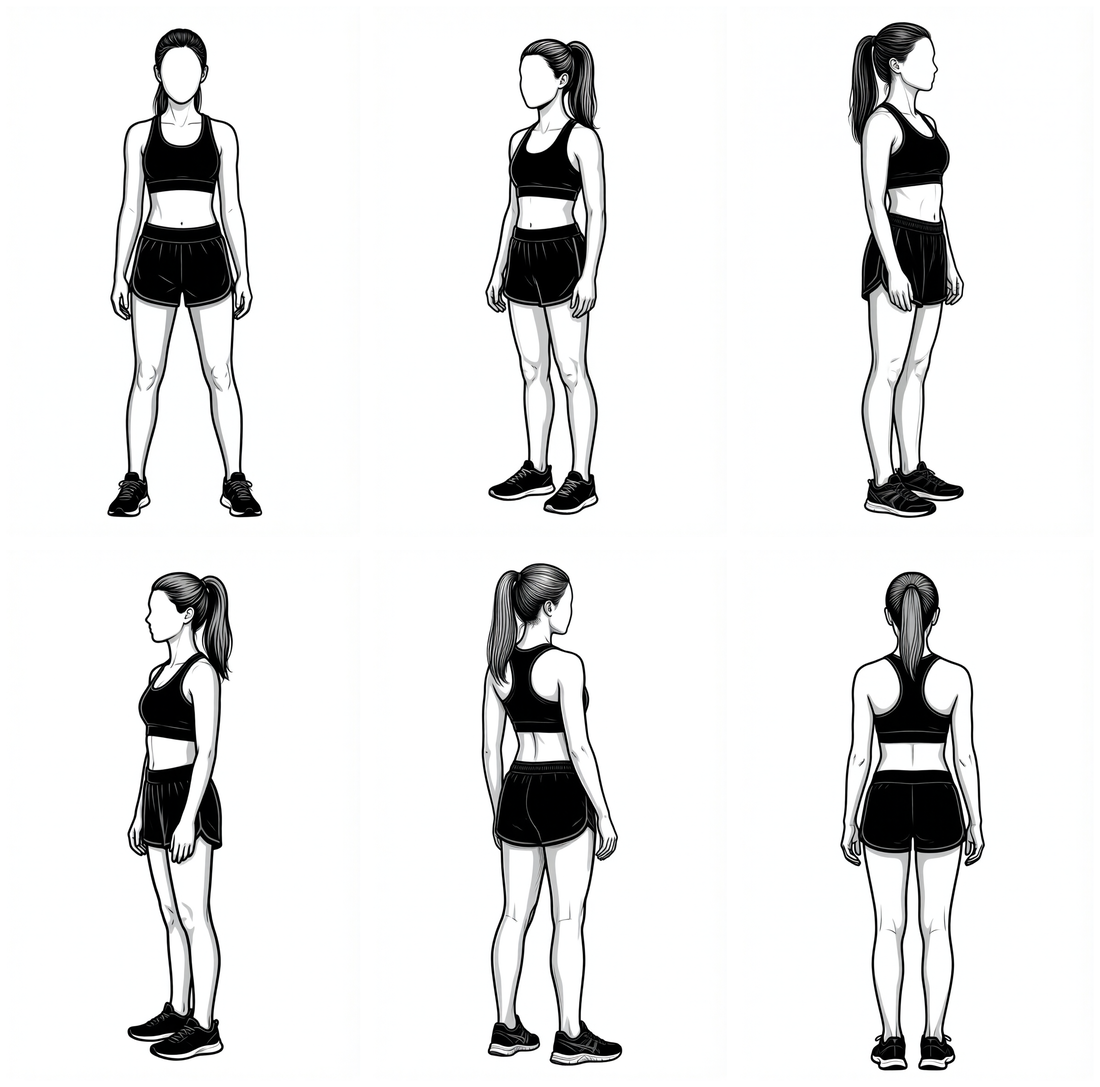
The pipeline chains several open diffusion models, each run quantised on the local GPU and driven through ComfyUI's API:
| Stage | Model(s) | Role |
|---|---|---|
| Pose extraction | DWPose (OpenPose) | a reference figure → a pose skeleton only |
| Repose → clean line | Qwen-Image-Edit + Qwen2.5-VL text encoder | redraws the house character into the target pose as a clean black line drawing |
| House-style restyle | FLUX.2 (Black Forest Labs) + Mistral text encoder | restyles the clean line into the warm hand-inked sepia house style |
| Line / diagram route | FLUX.1-dev + line-art LoRAs + ControlNet (OpenPose) | alternative clean-line diagram generation |
| Exercise video (in development) | Wan | mocap-retargeted animated exercise demonstrations |
Crucially, only the pose — a skeleton, which carries no likeness — is ever taken from a reference; the figure itself is generated fresh from a blank canvas, so no source photograph or person's likeness is reproduced. Every illustration is an original work.
Region line-art and a fallback library mean every topic shows a relevant illustration even before bespoke art is commissioned. Figures illustrate the referenced text; they are never themselves a clinical source.
Publication & architecture¶
15. Build & hosting. The finished knowledge base is built into a static site with
MkDocs + Material for MkDocs and deployed to a Cloudflare Worker (this site).
On-site search is Pagefind — a static, client-side index, so there is no search server
and no query logging. The practice clinic's /education pages embed this same content and
link to the PDFs hosted here.
16. Compute. The heavy lifting runs on local hardware: a GPU workstation runs the MedCPT embedding models and the language models used for synthesis; a server runs the vector and relational databases, the API, a second language-model endpoint and the publisher; network-attached storage holds the PDF library and the article store. Language models are served locally with llama.cpp behind an OpenAI-compatible API. (Specific network addresses and credentials are deliberately omitted.)
17. Models & frameworks.
| Role | Model | Framework |
|---|---|---|
| Embeddings + reranking | MedCPT (Query / Article / Cross-Encoder), 768-dim | PyTorch / Transformers |
| Scanned-PDF OCR | Qwen3.6 (35B, A3B mixture-of-experts), vision-language | llama.cpp |
| Synthesis — draft pass | Qwen3.5 (35B, A3B mixture-of-experts) | llama.cpp |
| Synthesis — augment / cross-reference pass | Gemma (26B, A4B mixture-of-experts) | llama.cpp |
| Patient voice + deep mode | Qwen3.6 (35B, A3B mixture-of-experts) | llama.cpp |
| Document parsing | docling + TableFormer; LiteParse | Python / Node |
The article store¶
The knowledge base is a simple tree — topics/<audience>/<region>/<slug>/ — where each
topic folder holds the article (synthesis.md), the gathered evidence (evidence.md),
its references and figures, and, for operations, the recovery sidecar. There are two
audiences (clinician and patient), and roughly 600 topics across the upper-limb regions
and beyond.
Open-source tooling¶
OrthoWiki stands on open-source work:
- MedCPT embeddings — huggingface.co/ncbi/MedCPT-Query-Encoder
- Qwen language models — huggingface.co/Qwen
- Gemma language models — Google on Hugging Face
- llama.cpp (local LLM serving) — github.com/ggml-org/llama.cpp
- PyTorch / Transformers — github.com/huggingface/transformers
- docling (PDF → Markdown, TableFormer) — github.com/docling-project/docling
- LiteParse (fast PDF text) — @llamaindex/liteparse
- Qdrant (vector database) — github.com/qdrant/qdrant
- pgvector (Postgres vectors) — github.com/pgvector/pgvector
- Material for MkDocs (site) — github.com/squidfunk/mkdocs-material
- Pagefind (static search) — github.com/CloudCannon/pagefind
- WeasyPrint (PDF handouts) — github.com/Kozea/WeasyPrint
- ComfyUI (local image-generation backend) — github.com/comfyanonymous/ComfyUI
- FLUX image models (Black Forest Labs) — huggingface.co/black-forest-labs
- Qwen-Image-Edit — huggingface.co/Qwen
- DWPose (pose extraction) — github.com/IDEA-Research/DWPose
- CrossRef (citation metadata) — crossref.org
- PubMed / NCBI (MeSH) — ncbi.nlm.nih.gov
- Cloudflare Workers (hosting) — workers.cloudflare.com
In short¶
Every page begins as an automated synthesis of the indexed literature, with each claim referenced to its DOI, and is then reviewed by a specialist before publication. It is an evidence aid and an educational resource — not a substitute for individual medical advice.